Is Attention All You Need?
Given the ease with which Transformers generalize, scale, and their efficiency on existing hardware, they have become the dominant architecture over the last ~7 years, achieving SoTA in most applications. That’s more true now than ever given that most of the researchers and developers are working on them, all major foundational models are Transformers, and their success carries the weight of trillions of dollars of market capitalization.
Yet, the technology lock-in effect isn’t insurmountable, and several new architectures have recently emerged designed to outperform full attention Transformers primarily at where they inherently struggle: long-context learning / generation and inference speed / cost.
These approaches include sparsified attention mechanisms, linear RNNs, and SSMs. Whereas Transformers seek to store all mappings of the past in memory and are thus limited by an ever-growing memory burden, these alternatives seek to distill the past and are thus limited by their ability to summarize with minimal functional loss and often struggle with recall (since they don’t store the entire input, they can’t recall the original segment).
Given these complementary skill sets, many of the top alternative architectures combine some form of sparse attention with an SMM or RNN block. This helps them retain the best aspects of both model architectures: the accuracy of full attention applied to the local context and the throughput + long context modeling of SSMs/RNNs.
While these alternatives have been shown to be of competitive quality with full attention Transformers of similar size, so far no model has been developed beyond 200M-14B active parameters. It took over three years for ChatGPT to scale from the current SSM & RNN model sizes to GPT-4’s 1.76T parameters.
Can these alternatives be scaled to such large sizes and remain sufficiently more competitive to shift the ecosystem’s center of gravity away from Transformers? Moreover, if they do so in a three year time span, will that work have caught up to GPT-6/7?
I focus on this challenge for architecture supremacy because, while progress will continue to happen in every other direction too, the long context arms race has implications for all kinds of use cases as seen below and pits tiny startups / research labs against Microsoft / Google / OpenAI. Plus, exploring the cutting edge of model architecture should become all the more important as we hit limits in our capacity to simply scale compute and data.
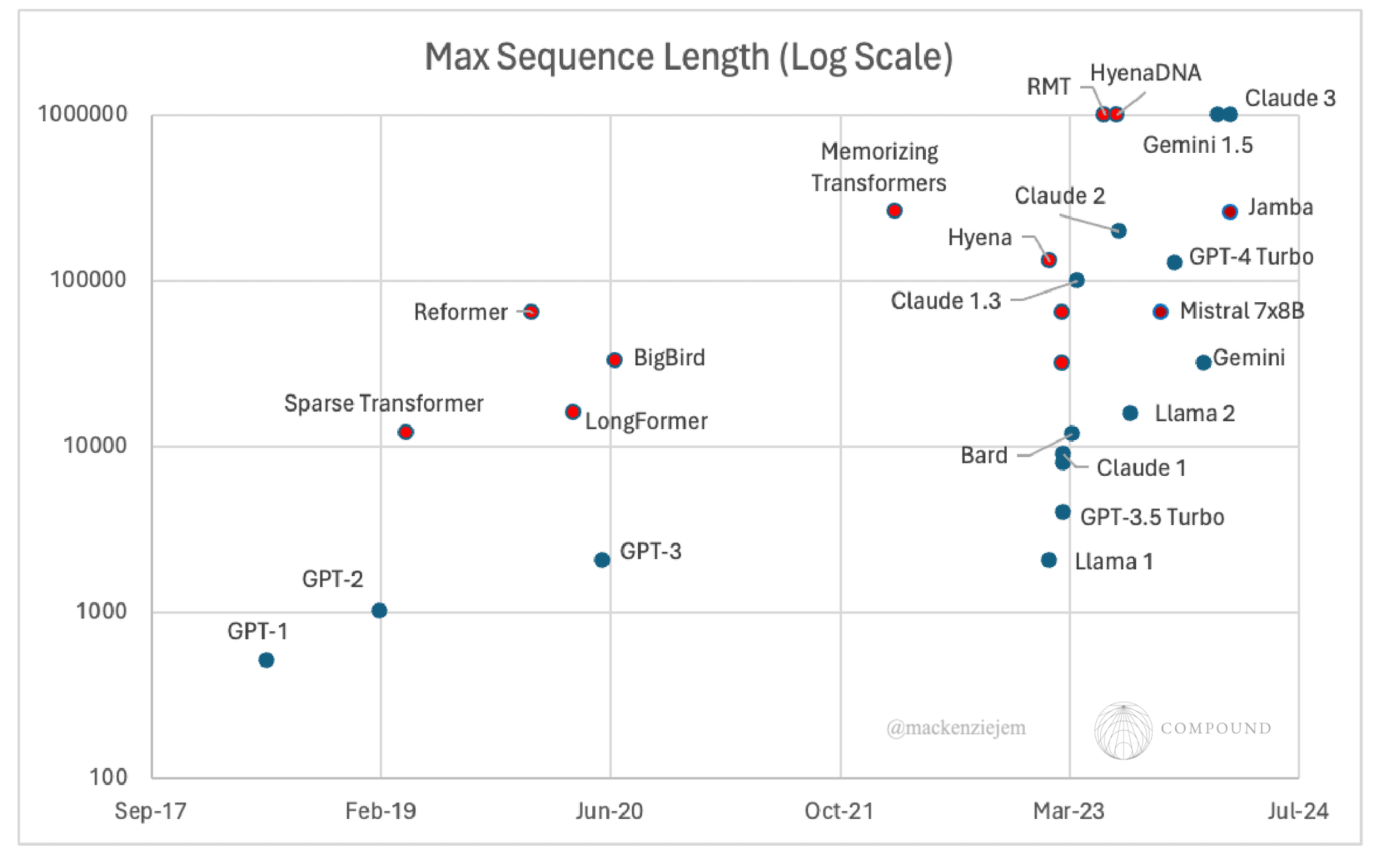
Note that the context length handled by the top attention-based models (ChatGPT, Gemini, Claude, etc.) has scaled exponentially over the last couple years and can now process up to 1M long inputs. These firms’ secrecy prohibits us from knowing whether they’re just eating the costs for the time being, if they use some form of sparse attention, or if they made other algorithmic improvements elsewhere in the model architecture. To the public’s knowledge, only relatively minor improvements have been made to the Transformer architecture. And, on the final point, the attention portion of the model accounts for roughly half of the compute / memory, so improvements made elsewhere are equally important. These possibilities are explored at the end of this paper.
Long context allows for:
- New use cases:
- Summaries of entire books or many documents in parallel
- Chatbots that remember your dialogue over time, possibly even ones that start to understand your personality or tendencies or interests
- Personal assistants as discussed on BG2 that have knowledge of your email, calendar, tendencies, etc. to be perform as well as a high-quality human EA.
- Coding tools that can understand projects’ entire GitHub repositories. This would mean a virtual coder capable of understanding the interdependencies of functions and files. The primary startup in this space, Magic Dev, released a model that can ingest 5M tokens (or ~500K lines of code or ~5K files) and claims to have achieved tens of millions context length internally.
- Tools to make sense of inherently long context data. Genetics is a great example of this. The human genome is 6 billion letters and it’s well documented that interdependencies can stretch across millions of base pairs. Hazy Research adapted their Hyena model to process 1M nucleotide token context lengths and achieved SoTA in 23/28 tasks. A Broad Institute researcher adapted a Transformer to be able to generate entire bacteriophage genomes with lengths up to 96kbp. More generally, time series, audio, video, medical imaging data naturally modeled as sequences of millions of steps.
- Analysis / generation of higher resolution images, videos, or vide-audio content
- Replacing fine-tuning as a means for organizations to make their proprietary data / information useful, as described by this engineer
- It also appears that longer context lengths makes a model “dramatically better at predicting the next token in a way that you'd normally associate with huge increments in model scale”
More efficient models / hardware:
- Meaningful increases in the economics of inference will also make viable things like autonomous agents such that an increasing share of web traffic are smart bots doing tasks for their deployers
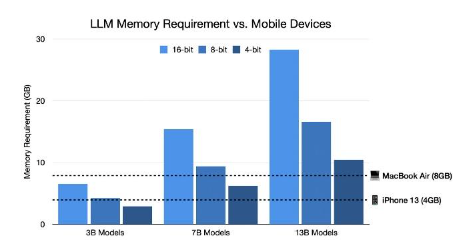
- Incremental increases in efficiency will enable capable models to be deployed on PCs and mobile devices, as seen to the right.
- Step function increases in efficiency will enable deployment on the edge. This will likely come from highly specific, analog devices. Dozens of chip designers are looking to instill intelligence into edge computing chips, physically programming them to be able to identify objects or noises with low energy. This could lead to highly efficient smart doorbells capable of learning the homeowner’s face without ever needing to relay to the cloud, thus saving not only on compute but also on privacy. Or, it could enable analog chips designed to listen for cues like “Hey Siri'' in a highly energy efficient manner, which when triggered would then turn on the more general purpose chips.
- More generalized intelligence with meaningfully similar efficiency will be important for use cases like truly useful Meta glasses.
Dramatically improved speed:
- Will yield not only a better user experience for things like chatbots and code (productivity will really be unleashed when developers wait 2 seconds for the token generation of their code suggestions instead of 10), but also enable fundamentally new possibilities. This includes chatbots that can talk in a live conversation over voice. It’s also essential for robotics. When you watch videos of the deployments of large models on robotics, they’re always sped up 4x. For these systems to be useful in live environments, they’ll need to be able to make decisions much faster.
- The speed of generation may also significantly improve the quality of generated results as it’ll enable generative models to become agentic systems of one model prompting suggestions and the core model revising its output. Just as humans produce better results when allowed to make outlines, drafts, edits and incorporate third party feedback, AI systems have been exhibited similar boosts to quality across use cases. The faster the models’ generation speeds, the more iterations and ideas the agentic system will be able to explore. See Andrew Ng’s posts for more.
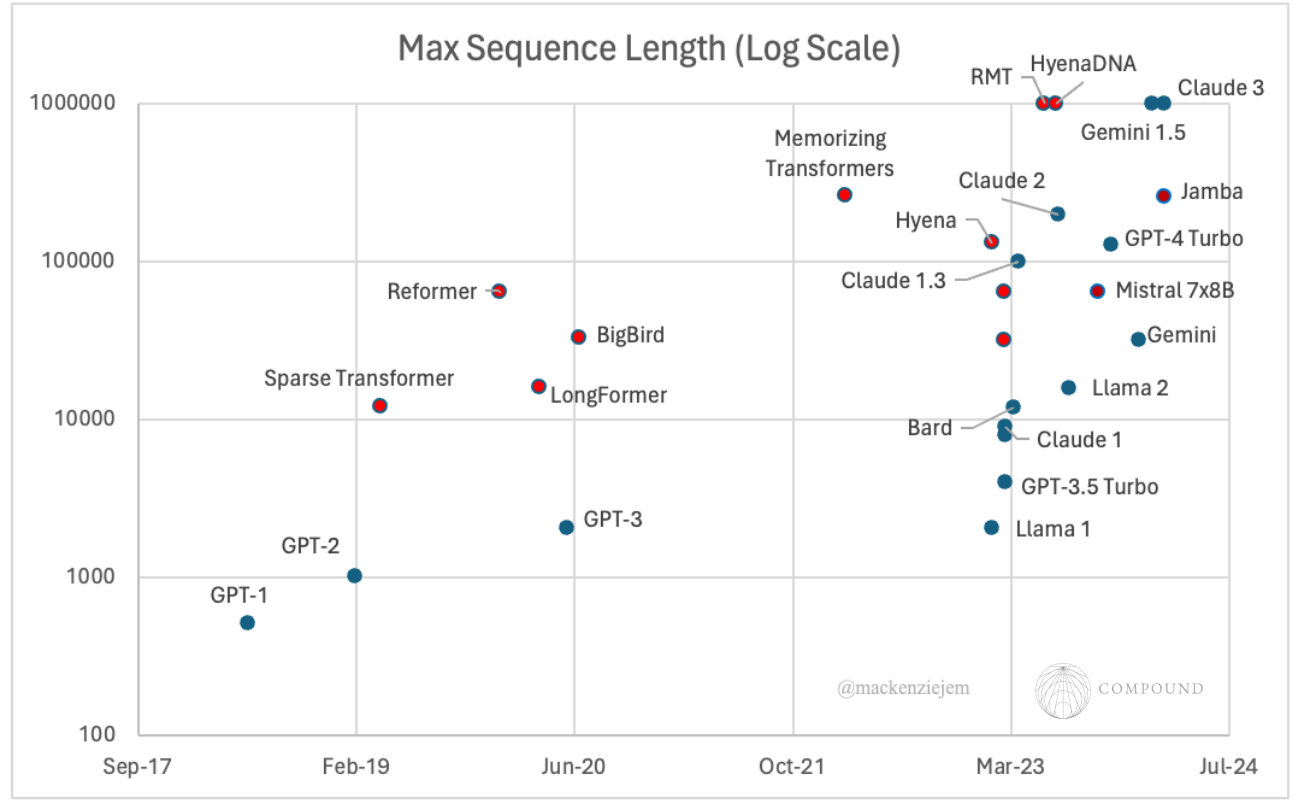
Note: red denotes sparse attention, RNN & SSM models. Blue denotes full attention.
Section I: Progress in Transformers Towards Subquadratic Attention
Section II: Potentially Transformative Alternative Architectures
- Linear RNNs, SSMs and More: alternatives to attention
- Takeaways from Alternatives
- Full database of models
- Overview of Selected Models
- Further Detail on Selected Models
Section III: Architecture-Agnostic Improvements Likely Favor Transformers
- Model Improvements
- Distributed Computing: moar GPUs pls☺
- Faster computing of attention:
- Sparsifying the feedforward side of Transformers: MoE
- Chips Advancements in Many Flavors: More Memory, Speedy Inference, and Interconnects at the Speed of Light
Section I: Progress in Transformers
Towards Subquadratic Attention: finding ways to compute less
[First, for primers on how Transformers work see the following: 1,2,3,4,5,6,7,8]
At the heart of Transformer’s architecture is the mechanism of self-attention, in which every token is mapped to every other token. In other words, as the model processes each additional inputted token, it concurrently processes every other token in the sequence. Attention is thus calculated by multiplying two large matrices of weights and passing it through a softmax function that normalizes the values. The values in each row and column of the resulting matrix represent correlations between words / their similarity score / how tightly they depend on one another. Modeling all possible interdependencies of words yields some great properties: “it can losslessly propagate information between any two entries in the sequence, regardless of their distance (global memory) and has the ability to extract information from any single element (precision).”1 In other words, it drives the accuracy, expressivity, flexibility, and recall capacity of modern large models.
The flipside of this is that Transformers must store in memory a matrix of size NxN where N is the sequence length. In other words, the models scale quadratically in sequence length (due to attention) and model dimension (due to MLP layers). Thus, Transformer’s uncanny ability to relate distant ideas comes at the cost of higher compute that increases quadratically. For more technical detail see this paper. This quadratic memory burden hurts their ability to model long sequences, speed during inference, and overall compute efficiency.
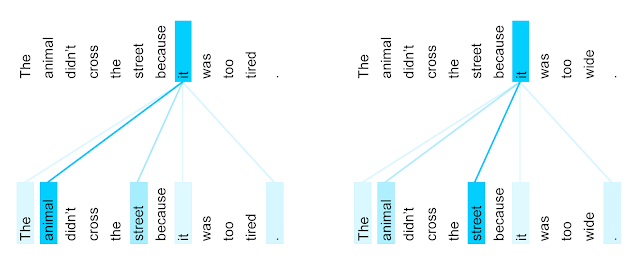
This inherent limitation of vanilla Transformers has led researchers to search for more efficient attention mechanisms. The intuition of subquadratic attention lies in the fact that in language modeling, a subset of words contributes most of the meaning. For example, a vanilla transformer would attend each word of the sentence, “I want to order a hamburger,” equally despite the words “I”, “order,” “hamburger” driving almost all the meaning. Though this is of course a simplification, it illustrates the idea.
Moreover, the pareto principle in language modeling illustrated by the example above is true as you zoom out from within-sentence mappings to long-range ones. The word “order” from this sentence has little to no direct connection to the meaning of a given word from a paragraph several pages prior. I.e. there’s locality to meaning. A word contributes more meaning to its neighbors than to those far, far away.
Indeed, this intuition is embedded in the computation due to the exponential nature of the softmax, which results in almost all values becoming near zero and only a few positions with high values. Moreover, several papers suggest that attention mechanisms only utilize a subset of their quadratic capabilities for language processing1,1.
One way to try to exploit the concentration of meaning in language is to make the attention matrix similarly sparse. In other words, to only allow each position to attend to a subset of the positions. Here are a very high level categorization of the approaches: (i) fixed and random, (ii) learned and adaptive, and (iii) identified with clustering and locality sensitive hashing. For more detailed breakdowns of the various approaches see the excerpt below:


If you want to go deeper, read these literature reviews: (1,1,2).
The sparse approaches can be visualized below:
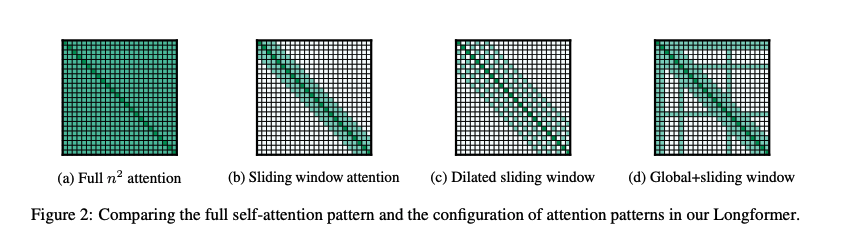
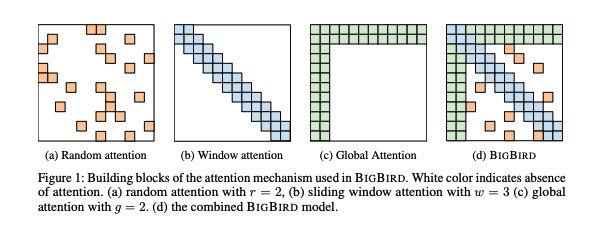
Despite this huge diversity of progress and much more unmentioned, the only major model to publicly acknowledge using subquadratic or approximate attention mechanisms is Mistral’s use of sliding window attention. Lukasz Kaiser (author of Attention is All You Need paper, some of the key sparse attention papers, and now scientist at OpenAI) recently patented a sparse attention mechanism. But, the fact that those are the most provocative announcements I could find points to how little it’s been deployed in top models compared to other conditional computing methods like sparse MoEs and quantization. As a top Google researcher said, “there's a graveyard of ideas around attention.”
Section II: Potentially Transformative Alternative Architectures
Linear RNNs, SSMs, and More: alternatives to attention
Both RNNs and SSMs have decades long histories, but only in the last several years, sufficient architectural tweaks have produced credible alternatives to Transformers. In fact, there's a bet going on between the chief scientist at MosaicML and a research scientist at Hugging Face on whether or not a Transformer-based model will still hold the SoTA in 2027.
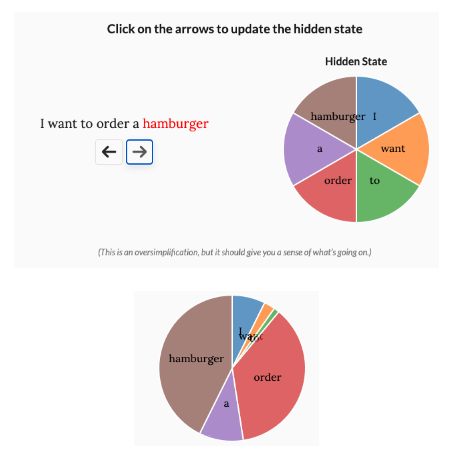
RNNs model a hidden state at each time step, updating it as each new input data is encountered. The state size is typically fixed and stored as a single vector. So, as time goes on, the model aims to distill and summarize the data with minimal loss and maximal signal. Such internal state can capture the long-term behavior of a system over time reasonably well without having to store the entire input in working memory.
However, they historically haven’t scaled well because of issues like the vanishing gradient problem and training issues due to their sequential, non-parallelizable time dimension. They’ve also historically struggled on information dense data like language because of their tendency to overweight the recent past.
As illustrated by the diagram below, they work by applying a function to input u to transform into an intermediate hidden state x before outputting y. The hidden state is updated like this step by step. This makes for slower training speed with traditional RNNs because you need to wait to compute the next hidden state before computing the value but faster inference because you can just go from the last hidden state whereas attention requires full look back across all inputs for generation.
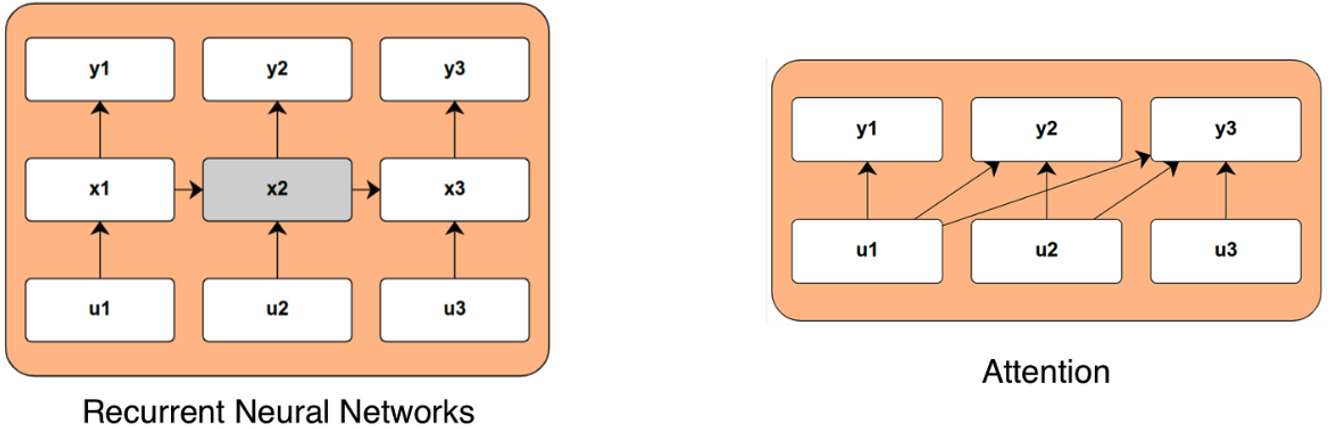
In summary, whereas Transformers seek to store all mappings of the past in memory and are thus limited by an ever-growing memory burden, RNNs seek to distill the past into a fixed state size and are thus limited by their ability to do so with minimal functional loss. Said differently, if you keep everything in memory, you get high accuracy and recall with low speed, and vice versa for methods that prune memory.
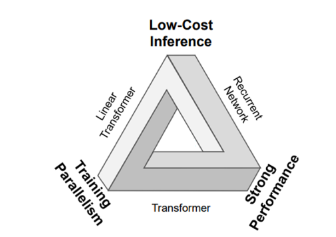
An explosion of alternatives to attention & Transformers over the last four years has sought to retain the fixed state space of RNNs and their quick inference while making their training parallelizable and their state more expressive. In other words, they aim to expand the Pareto frontier of the impossible triangle as seen to the right or at least make reasonable speed vs accuracy tradeoffs to address unmet market needs.
These models’ reduced memory footprint combined with any fundamental architectural advancements that expand the Pareto frontier yields them several to many times faster inference. For example, Mamba has 5x higher throughput than a Transformer.
Linear RNNs (including their variant, SSMs) model the hidden state at each step as a linear combination of the previous hidden state and the current input. This, upon some nice mathematical distillation, makes it possible to run a 1D convolution of the input data either via either a Fourier transform or an associative scan. This circumvents the fatal flaw of prior RNN implementations – their serial nature, which made training impossibly slow relative to Transformers – and instead makes the models parallelizable.
The latest SSMs are a clever parameterization of linear RNNs that combine ideas from CNNs, RNNs, and attention depending on the exact model. As Albert Gu described:
The idea is that instead of going from the input to the state to the output you can go straight from the input to the output, bypassing the state and doing the entire computation over the sequence length in parallel. SSMs turn out to be equivalent to convolutions because computing the map from the input u to the output y is equivalent to convolving the input by a particular convolution filter. So, to compute this map you just do: y equals u convolved with k for this convolutional kernel.
Here's a more technically involved definition:
Structural SSMs achieve such impressive performance by using three main mechanisms: 1) High-order polynomial projection operators (HiPPO) (Gu et al., 2020a) that are applied to state and input transition matrices to memorize signals’ history, 2) diagonal plus low-rank parametrization of the obtained HiPPO (Gu et al., 2022a), and 3) an efficient (convolution) kernel computation of an SSM’s transition matrices in the frequency domain, transformed back in time via an inverse Fourier transformation (Gu et al., 2022a).
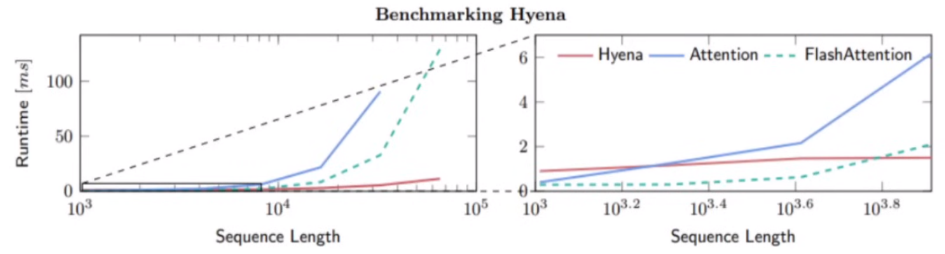
Like SSMs scale with O(NlogN) in sequence length, instead of O(N2) for attention. They of course have their drawbacks, which often include the following:
SSMs are a bit complex - to train in a modern deep learning stack, they rely on sophisticated mathematical structures to generate a convolution kernel as long as the input sequence. This process can be unstable, and requires careful initialization for good quality. (from Hazy Research)
Certain implementations of the architecture can also run into other issues like Fourier transforms not being supported on TPUs. Finally, many variants have struggled with associative recall and retrieval.
Key takeaways from alternative models:
For models relying on fixed state spaces, input-dependent gating / dynamically selecting what input data to remember seems crucial to preserving only the most important info. This contrasts to static mechanisms that remember data based solely on its position in the matrix. Indeed, one of the Mamba authors stated that “It seems that data-dependent gating is the core ingredient for effective linear-complexity alternatives to softmax attention, as shown in both our GLA and Mamba.”
Another key architectural design takeaway is that combinations of complementary mechanisms appear most effective. As one of the most prominent researchers in the SSM field said: “one principle that was validated over and over again (and we're trying to understand better now) is that it seems composing hybridizing different layers with blocks from different categories is better than the individual components.” Indeed, many of the top models combine some form of sparse attention with an SMM or RNN block. This may retain the best aspects of both models: the accuracy of dense attention applied to localized context with the throughput and long context modeling of SSMs/RNNs. Additionally, the models that integrate some Transformers blocks into an SSM architecture have shown improved capacity for retrieval and particularly needle-in-a-haystack problems. It's thought that SSMs lack so-called retrieval heads.
These new alternative architectures join the sparse attention efforts on the march from quadratic compute to increasingly linear compute, albeit from a different starting point. Indeed, all these different mechanisms and approaches often overlap conceptually and practically as they converge on the common end goal: getting rid of unnecessary data and computation. As time moves on and it becomes more clear which approaches are most consistently and universally promising, the concentric circles may get ever tighter.
For some specific examples of how these mechanisms are not just conceptually similar but can even be reformulated as effectively the same thing, see this word game from Sasha Rush: “Attention and RNNs are distinct, but Linear Attention is a Linear RNN, but not vice versa. Luckily both are also Convolutions.... but not with data dependent parameters.” Additionally, here’s the paper demonstrating linear attention can be viewed as a linear recurrence. Finally, a recent paper showed that Mamba blocks can be reformulated as an implicit form of causal self-attention.
While these alternatives have been shown to be of competitive quality with full attention Transformers of similar size, so far no model has been developed beyond 200M-14B active parameters. It took over three years for ChatGPT to scale from the current SSM & RNN model sizes to GPT-4’s 1.76T parameters. Can these alternatives be scaled to such large sizes and remain sufficiently more competitive to shift the ecosystem’s center of gravity away from Transformers? Moreover, if they do so in a three year time span, will that work have caught up to GPT-6/7?
If these models truly offer legitimate promise to be competitive accuracy-wise with far higher throughput / efficiency, then why hasn’t one of the groups secured $10-100M in investment to scale them up and push them to their limits? Why haven’t they been tested beyond 14B parameters? One possible explanation is that Transformers have been a relatively static architecture since their conception 7 years ago, with only minor subcomponent tweaks having taken place. Much of the ecosystem developer and financial resources have been devoted to scaling and deploying the architecture. Whereas, within the Cambrian explosion of alternative architectures, on a monthly basis entirely new architectures are invented with some achieving SoTA. Until the ecosystem saturates the explorable universe and a clear champion arises, companies with the resources to fund the training of a massive model have an incentive to wait for that day.
Additionally, we may see different LLM architectures based on the task at hand. SSMs have long been superior at modeling signal / continuous data. They may successfully creep into Transformers’ sequential data domain as well. It may even possible that systems like ChatGPT will use multiple different architectures. Meta just released a paper where they trained “multiple independent LLMs that do not share any parameters and each LLM is an expert specializing in its own data distribution, such as knowledge domains, languages or even modalities. At test time, an input prompt is classified into one or more of the domains, and then the final outputs are formed from the corresponding expert models which are combined to predict the next token.” Who knows, maybe it’s possible to do something similar with different mechanisms (ex. full attention if short input; else, linear attention) or even different architectures (ex. full attention if short input; else, Mamba) not just data sets?
Finally, as to where this research comes from, the vast majority of the high impact sparse attention papers originate from Google and the SSM / RNN papers from Hazy Research. These pockets of innovation in architectural design follow a trend in AI research where roughly every 5 years a new idea that’s sufficiently novel and powerful is introduced, and a transient burst of experimentation ignites. RNNs were followed by variants like gated RNNs (e.g. LSTM), attention by sparse attention mechanisms, and now S4 by a slew of linear RNN and SSM variants. Eventually, the universe of possibilities is explored and the experimentation subdues, giving way to the similarly valuable but incremental work of refinement, scaling, and application – until another fundamentally new idea is broached.
Overview of Selected Models
[Note that I focus on language models, but non-attention architectures are relevant for other types of models (ex. a group made an SSM-based diffusion model) as well as other data domains (see the “Derivative Models” column of the Excel file).]
Mamba: improved upon S4 by introducing selectivity / input dependence via a gate without reverting to RNNs’ sequential nature, making the model more expressive
StripedHyena: exemplifies how hybrid models may be optimal, as it combines convolutions attention and gated convolutions
- “Early in our scaling experiments, we noticed a consistent trend: given a compute budget, architectures built out of mixtures of different key layers always outperform homogenous architectures. These observations echo findings described in various papers: H3, MEGA (among others) and find even earlier connections to the hybrid global-local attention design of GPT-3 (from Sparse Transformers) and GPTNeo.”
Based: improved upon Mamba by addressing the serious limitations in recall of it and other SSMs by combining short convolutions and linear attention
- Efficient architectures (e.g. Mamba) are much faster than Transformers at inference time (e.g. 5x higher throughput) in large part because they have a reduced memory footprint. Smaller memory footprint means larger batch sizes and less I/O. However, it also makes intuitive sense that reducing memory footprint too much could hurt a model’s capacity to recall information seen earlier in the sequence. (Together AI)
- Found that gated-convolution models’ poor performance on associative recall tasks account for >82% of the remaining quality gap as measured by perplexity to attention on average. A 70M attention model outperforms 1.4Bn Hyena on AR tokens.
Griffin / Hawk: hybrid combination of gated linear recurrences similar to Mamba’s blocks and local attention. Like Based, it’s capable of efficiently copying and retrieving data over long horizons. The authors also reinforce the importance of gated recurrences. Finally, the paper demonstrated that Google is actively exploring alternatives to attention.
Jamba: another hybrid model combining Mamba blocks with attention that’s scaled up to 52B total parameter MoE model with 12B active parameters. It achieves similar quality to Mistral but with 3x better throughput. It can fit on a single 80GB GPU and is accessible via API.
Monarch Matrix: first model to replace both attention and MLPs that matches equivalently sized Transformers (360M parameters)
Further Detail on Selected Models
Mamba:
S4 precomputes the convolutional kernel. Mamba introduced selectivity (like sparse attention) such that the matrices change depending on the input. Mamba’s gate allows it to reset its state and forget any information it holds from the past. However, dependence on the input requires training it like an RNN where it must be updated sequentially for each token. So, Mamba's second major idea involves training in RNN mode very quickly. At some point, Gu and Dao realized that their recurrence was very similar to a scan algorithm, also known as a prefix sum. As a result, we can compute this prefix sum (or scan) operation in roughly O(logN) time. Moreover, as Dao was the lead author of FlashAttention, he came up with the clever hardware-aware implantation in which it stores the latent state in SRAM, the most efficient part of memory.
The author of LSTM echoed the importance of Mamba’s gates: “I always felt that S4-related nets didn’t work well because they were missing the two core LSTM ingredients: fast weight gates + cell skip connections. This seems to bring both of those back.” One of the Mamba authors stated that “it seems that data-dependent gating is the core ingredient for effective linear-complexity alternatives to softmax attention, as shown in both our GLA and Mamba.”
See Jack Cook’s blog for more
StripedHyena:
- First alternative model competitive with the best open-source Transformers (Llama-2, Yi and Mistral 7B) in both short and long-context evaluations on OpenLLM leaderboard. It outperforms on long-context summarization.
- Designed using our latest research on scaling laws of efficient architectures. In particular, StripedHyena is a hybrid of attention and gated convolutions arranged in Hyena operators. Via a compute-optimal scaling protocol, we identify several ways to improve on baseline scaling laws for Transformers (Chinchilla) at the architecture level, such as hybridization. With these techniques, we are able to obtain higher quality models than Transformers at each training compute budget, with additional benefits at inference time.
- Optimized using a set of new model grafting techniques, enabling us to change the model architecture during training. StripedHyena was obtained by grafting architectural components of Transformers and Hyena, and trained on a mix of the RedPajama dataset, augmented with longer-context data.
- Using our latest research on fast kernels for gated convolutions (FlashFFTConv) and on efficient Hyena inference, StripedHyena is >30%, >50%, and >100% faster in end-to-end training on sequences of length 32k, 64k and 128k respectively, compared to an optimized Transformer baseline using FlashAttention v2 and custom kernels. StripedHyena caches for autoregressive generation are >50% smaller than an equivalently-sized Transformer using grouped-query attention.
From <https://www.together.ai/blog/stripedhyena-7b>
Based:
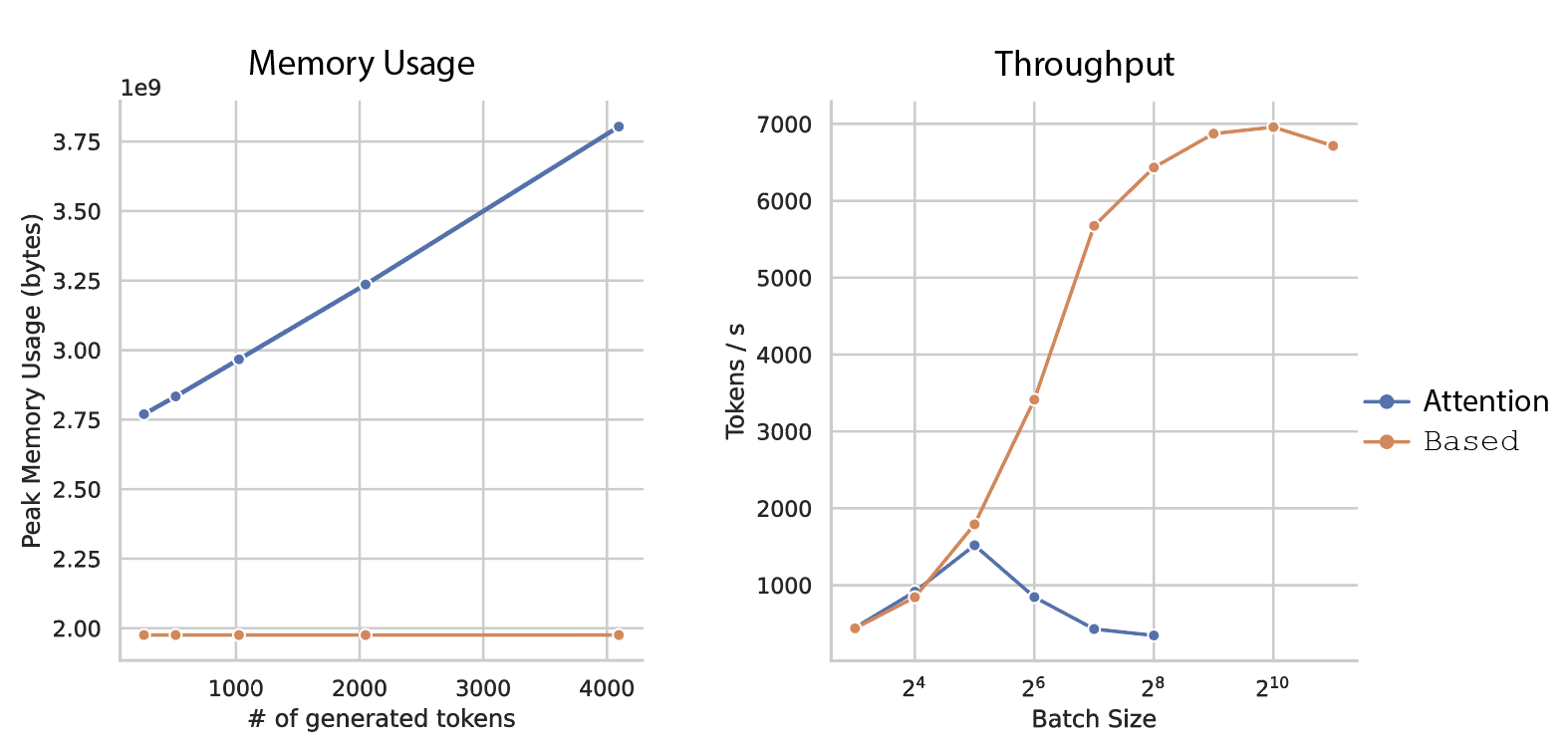
Based is a simple architecture that combines two familiar sub-quadratic operators: short convolutions and linear attention. These operators have complementary strengths and together enable high-quality language modeling with strong associative recall capabilities. At inference time, because Based only uses fixed-sized convolutions and linear attentions (computable as recurrences), we can decode with no KV-cache. This enables a 4.5x throughput improvement over Transformers with Flash Attention 2.
We demonstrate these properties along three axes, finding that Based provides:
- We motivate Based with the view that simple convolutions and attentions are good at modeling different kinds of sequences. Instead of introducing new complexities to overcome their individual weaknesses, we can combine familiar versions of each: standard convolutions are great for modeling local dependencies and settings where we might not expect to need associative recall (think building up morphemes [i.e., units of meaning] from individual tokens, similar to how in vision we build up higher-level features from neighboring pixels). Meanwhile, a spiky linear attention calculated as a Taylor approximation of softmax enable Based to do associative recall, e.g., by recovering the global “look-up” inductive bias of standard attention 1. As we’ll see, the combination of both enables Based to achieve high quality sequence modeling while remaining *fully sub-quadratic*.
- High quality modeling: despite its simplicity, in our evaluations we find Based outperforms full Llama-2 style Transformers (rotary embeddings, SwiGLU MLPs, etc.) and modern state-space models (Mamba, Hyena) in language modeling perplexity at multiple scales. (Section 2. Based outperforms Transformers in language model perplexity.)
- Efficient high-throughput inference: when implemented in pure PyTorch, Based achieves 4.5x higher inference throughput than competitive Transformers, e.g., a parameter-matched Mistral with its sliding window attention and FlashAttention 2. High throughput is critical for enabling batch processing tasks with LLMs. (Section 3. Based is fast.)
We found that there is a small perplexity gap between recently proposed sub-quadratic gated-convolution architectures and Transformers, when training on fixed data (10B tokens of the Pile) and infrastructure (EleutherAI GPT-NeoX). However, after performing a fine-grained error analysis, we see there remains a significant gap on next-token predictions that require the model to deploy a skill called associative recall (AR).
What’s AR? Consider the sequence: “She put vanilla extract in her strawberry smoothie … then she drank her strawberry?” – the model needs to be able to look back at the prior context and recall that the next word should be “smoothie”. We find that the gated-convolution models’ poor performance on these sorts of token predictions account for >82% of the remaining quality gap to attention on average! A 70M attention model outperforms 1.4Bn Hyena on AR tokens.
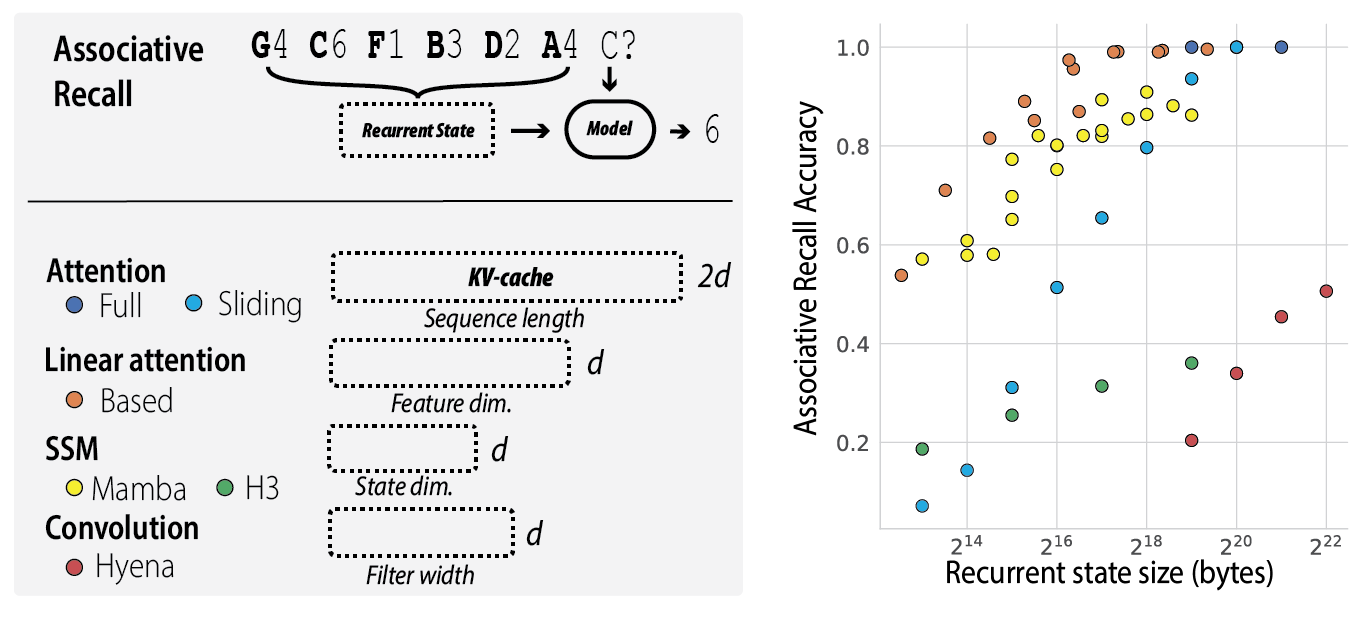
Efficiency. We also note that in contrast to prior work (H3, Hyena, Striped Hyena, Multi-Head Hyena, M2, BIGS, etc.), the block does not use convolutions where the filter is as long as the input sequence. The use of short convolutions plus linear attention permits parallel training and recurrent inference, without requiring any further modifications like distillation.
Because linear attention can be viewed as a recurrence and short convolutions only require computing over the last filter-size terms during generation, Based’s hidden states only require constant memory; no KV-cache or growing with generated sequence length!
From <https://hazyresearch.stanford.edu/blog/2023-12-11-zoology2-based>
Griffin / Hawk:
We propose Hawk, an RNN with gated linear recurrences, and Griffin, a hybrid model that mixes gated linear recurrences similar to Mamba’s block with local attention. We have found this fixed state size combination extremely effective, since local attention accurately models the recent past, while the recurrent layers can transmit information across long sequences. Hawk exceeds the reported performance of Mamba on downstream tasks, while Griffin matches the performance of Llama-2 despite being trained on over 6 times fewer tokens. We also show that Griffin can extrapolate on sequences significantly longer than those seen during training and are capable of efficiently copying and retrieving data over long horizons.
Gate behavior:
- The input gate 𝑖𝑡 is similar to the one in LSTM, which can filter (or scale down) the input 𝑥𝑡. However, to our knowledge, our recurrence gate 𝑟𝑡 is different from other gating mechanisms in the literature. For example, the selection mechanism proposed in Mamba (Gu and Dao, 2023) is comparable to the update gate of GRUs which interpolates between the previous state and the current observation 𝑥𝑡. Its effect on the hidden state allows it to reset its state and forget any information it holds from the past, similar to the forget gate in the LSTM. In contrast, our recurrence gate can approximately interpolate between the standard LRU update from Orvieto et al. (2023a) and the previous hidden state, which allows it to effectively discard the input and preserve all information from the previous history (see Appendix A for further details). We believe the key role of this gate is to enable the model to achieve super-exponential memory by reducing the influence of uninformative inputs.
From <https://arxiv.org/pdf/2402.19427.pdf>
Monarch Mixer:
- M2 matches GPT-style Transformers at 360M parameters in pretraining perplexity on the PILE--showing for the first time that it may be possible to match Transformer quality without attention or MLPs.
- We replace attention by using Monarch matrices to construct a gated long convolution layer, similar to work like H3, Hyena, GSS, and BiGS. Specifically, Monarch matrices can implement the FFT, which can be used to compute a long convolution efficiently: M2 uses Monarch matrices to implement a gated long convolution, by implementing the convolution using FFT operations.
- We replace the MLPs by replacing the dense matrices in the MLP with block diagonal matrices: M2 replaces dense matrices in an MLP with block-diagonal matrices.
- Incidentally, this makes the model look similar to MoE models, without learned routing.
From <https://www.together.ai/blog/long-context-retrieval-models-with-monarch-mixer>
Jamba:
- Joint Attention and Mamba (Jamba) architecture. Each Jamba block contains either an attention or a Mamba layer, followed by an MLP, producing an overall ratio of one Transformer layer out of every eight total layers. This ratio was optimized during research. Jamba uses a total of 4 attention layers.
- 52B total parameter MoE model with 12B active parameters
- Created by enterprise model developer AI21 Labs, it’s a production-grade model that’s currently accessible for use via Nvidia API and Hugging Face
- The only model in its size class that fits up to 140K context on a single 80GB GPU
- 3X throughput on long contexts compared to Mixtral 8x7B
- Reports good results on needle-in-a-haystack, retrieval, and in-context learning evaluations – the three of which are often downsides to pure SSM/linear RNN models.
From <https://arxiv.org/pdf/2403.19887.pdf>
Section III: Architecture-Agnostic Improvements Likely Favor Transformers
Model Improvements
The factors below could lighten the relative disadvantages of attention / Transformers in speed, efficiency, and throughput to maintain or extend their edge as the universal architecture. More specifically, it’s possible there’s a minimum threshold of context necessary to sustain dominance as a general purpose foundation model architecture – say, 1M tokens (~10 books or full GitHub repositories). Beyond that, only specific tasks will require anything more extreme (ex. personal assistants or full genome DNA analysis). With the computational and algorithmic approaches below (as well as possibly some of the sparsified mechanisms above), major Transformer models in the wild have already reportedly achieved that threshold (ex. Google’s Gemini and Anthopic’s Claude 3 both have a context length of 1M). Any further architecture-agnostic improvements will continue to disproportionately improve Transformer’s relative position.
a) Distributed Computing: moar GPUs pls☺
This method aims to circumvent the limited memory of individual GPUs/TPUs. The input sequence is split up and distributed across multiple devices. Ring attention, which gained notoriety after rumors that Google’s latest Gemini models with up to 1-10M context length relies on it, rearranges the computation in a metaphorical ring, with each GPU / TPU device processing its assigned segment and sharing only crucial information (key-value pairs) with the next device in the ring to compute attention and feedforward. This enables attention computation across the full sequence without requiring the entire memory to be present on a single device. Moreover, it enables sequence training and inference size to scale linearly with the number of GPU count without making approximations to attention or additional / overhead computation. The original UC Berkeley research team exceeded a context length of 100M (the number depends on the model size and GPUs available). In tests, the 13B parameter model yielded competitive accuracy to Claude 2 & GPT3.5. The group used it to build a 7B parameter model capable of analyzing and generating video, image, and language with a 1M sequence length that outperforms GPT-4V and Gemini Pro at 1hr+ long video analysis. Another group since published a paper purportedly making improvements to the ring attention architecture.
Meanwhile, a group recently used a distributed computing technique to speed up the inference of high resolution images and video from diffusion models by 6x on eight A100s with no quality degradation.
b) Faster computing of attention:
FlashAttention is fast and memory-efficient algorithm that computes the exact attention. FlashAttention is 2-4x faster than standard attention. It achieves this enormous increase in compute efficiency by restructuring how GPUs compute attention such that the bottleneck (memory not FLOPs) is addressed by minimizing reads and writes to HBM.
For more detail read the following:
It uses two main techniques: tiling and recomputation. Tiling happens in forward pass and it involves splitting large matrices in attention(K key and V value) into blocks. Rather than computing attention over entire matrices, FlashAttention computes it over blocks and concatenate the resulting blocks saving a huge amount of memory. Recomputation happens in backward pass and it basically means recomputing the attention matrix rather than storing it in forward. The idea of FlashAttention boils down to improving the memory and not decreasing computations because modern GPUs have high theorical FLOPs (which means you want to max that out) but limited memory12 (which means any saving in memory can improve the training speed). HBM is typically large but it is not faster than on-chip SRAM and thus, the computations over blocks (of K and V) happens in SRAM (because it is faster) but all full matrices are stored in HBM (because it’s big). This high-level explanation is probably an over-simplication provided that FlashAttention is implemented at the GPU level (with CUDA software) and this is in fact the reason why it is IO aware but hopefully that explains what’s going on in this fast algorithm.
Ideally, we would want the bulk of computations to be taken by matrix multiplication(matmul) operations but surprisingly, dropout, softmax, and mask (i.e, GPT-2 is decoder model) end up taking the whole runtime in GPT-2 attention because they are computed over full matrices. Matmuls take less runtime than those other operations because GPUs are exactly designed to be fast at matrix multiplications(they have really high theorical FLOPs and maximizing FLOPs usage doesn’t reduce the runtime). By using tiling and recomputation techniques, the compute time of FlashAttention is significantly low compared to standard attention as you can see below. See Tri Dao’s video for more.
FlashAttention-2 improves upon FlashAttention-1 by parallelizing over sequence length dimension instead of batch size and number of attention heads and splits Q(query) matrix instead of K and V. This release blog post explains well what FlashAttention2 brings to the tensor table.
Other methods of speeding up attention include quantization, speculative decoding, etc. An exciting recent Google paper thoughtfully combines multiple such methods to purportedly achieve “near-lossless 4-bit KV cache compression with up to 2.38x throughput improvement, while reducing peak-memory size up to 2.29x.”
c) Sparsifying the feedforward side of Transformers: MoE
Note that most of the top proprietary models used sparsified MoE protocols (Mistral, Gemini, etc.)
The compute costs of the self-attention mechanism contributes partially to the overall compute cost of the Transformer. A non-trivial amount of compute still stems from the two layer feed-forward layers at every Transformer block (approximately half the compute time and/or FLOPs). The complexity of the FFN is linear with respect to sequence length but is generally still costly. Hence, a large portion of recent work have explored sparsity (Lepikhin et al., 2020; Fedus et al., 2021) as a means to scale up the FFN without incurring compute costs.
Due to their computational demands, feed-forward layers in Transformers have become the standard target of various MoE techniques (Lepikhin et al., 2020; Fedus et al., 2022; Du et al., 2022; Zoph et al., 2022). Scaling properties and generalization abilities of MoE Transformers have been studied more closely by Artetxe et al. (2021); Clark et al. (2022); Krajewski et al. (2024).
Again, this approach could and has been used for RNNs/SSMs but I’d assume it'd dipropionate improve Transformer’s relative position.
For more detail on other methods to make models more efficient see these reviews: (1,1,2)
Chips Advancements in Many Flavors: More Memory, Speedy Inference, and Interconnects at the Speed of Light
I’d expect most of the inevitable advancements in chips to similarly play in Transformer’s favor for most applications.
- The latest competitor to NVIDIA to generate buzz, Groq focuses on making AI chips that offer super-fast token generation. See my write-up on the company and their approach. Their video demonstrations at speeds of 480 tokens / sec are 3-4x standards. They’ve even since reported 800 tokens / sec. Groq’s deterministic hardware design in which the sequence of operations must be pre-defined advantages any model inherently expressed that way, namely Transformers. It would presumably not work for any data dependent or time variant model architectures. Plenty of other companies are trying to make AI ASICs that accelerate performance well beyond Jensen’s master plans. One’s even trying to “Etch” the Transformer architecture into silicon. These are speculative ventures unlikely to prevail over NVIDIA given they use the same fundamental materials and approaches as Nvidia, in addition to how excellent and reasonably well specialized Nvidia’s products already are and their newly announced one-year product cycle. Either way, the speed of AI accelerator inference will improve whether it be incrementally or in a step function. That should favor Transformers.
- Photonic computing has taken major strides in recent years towards implementation in real chips. Several billion dollars have been raised by the several dozen photonics startups, with top ones like Lightmatter and Ayar inking deals with the top chip designers and fabs. In a recent interview I conducted, a Lightmatter engineer seconded my suspicion that optical interconnects are 3-5 years away from being integrated into chips. Enabling GPUs to communicate with one another at the speed of light melds their individual memories into one collective memory pool, helping evolve the unit of compute from individual GPUs to racks. This should make ring attention and other distributed computing approaches meaningfully more effective.
- The one I’m unsure about is how the near doubling of GPU memory size every two years will affect the architecture competition. It may favor fixed state models because you can store a larger state: i.e. you don’t have to distill so much of the information. Easing this bottleneck for those models would help with both accuracy and retrieval tasks, while only effecting speed in an incremental way.
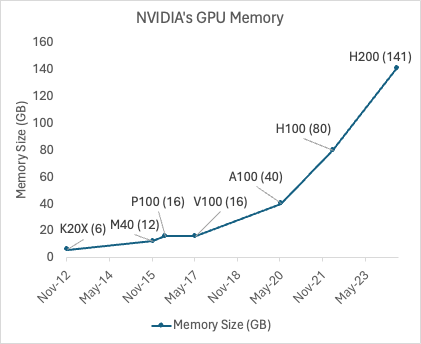
[The H200 is expected to nearly double the memory available to 141 GB and to release in Q2.
In summary, the dynamics identified in Section III suggest that the longer that Transformer alternatives take to decisively outperform, the less likely it will ever happen. This isn’t to mention developer and enterprise lock-in.
Conclusion
For the first time since their invention, Transformers have real competition. Several models in the 1-14B active parameter range have achieved similar quality scores as SoTA Transformers (e.g. Mistral) with far longer context and / or higher throughput.
The rate of iteration and progress in this subfield seems as rapid as any in artificial intelligence. Researchers are devising entirely new compute mechanisms like the Mamba blocks and Monarch Mixers; iteratively improving, generalizing, and distilling those mechanisms; and then trying all possible permutations of mechanism combinations.
On a near monthly basis, a new architecture is released that pushes the field or at least contributes meaningfully to our understanding of what makes a good architecture. Such high level findings include that hybrid models combining complementary mechanisms appear superior and that data dependent input gating is important to effectively distilling the past to a limited state size.
This competition for architectural supremacy is part of an inevitable march towards more efficient AI models. The room for far greater efficiency is a natural reflection of the fact that meaning is highly concentrated in a small proportion of words and that the same amount of compute shouldn’t be applied to predict every token or to solve every problem. Over time, efforts like those described above will find ways to compress information more lossessly and apply compute more intelligently.
It’s impossible to know whether a sparse attention mechanism, an SSM, a linear RNN, an approach yet to be invented or some combination therein will reign supreme in 3+ years – especially until each is demonstrated at scale. But I have confidence that SoTA models won’t use vanilla full self-attention forever.
The Pareto frontier will continue to expand such that longer context modeling and / or greater inference throughput and cost will be possible without significant quality losses. As that frontier expands, so do the number of use cases for AI.