Towards Material Abundance

The ages of man are named and defined by materials from the stone age onward. Solving each of humanity’s core problems from energy to climate to compute requires radical materials innovations. Here are a few of the world-changing materials we at Compound are excited about:
- Reducing PEM electrolyzers' reliance on Iridium (more expensive than gold) by 80%+ with new catalysts or nanoporous membranes with extreme surface areas
- Other catalysts, MOFs and membranes for carbon capture, upcycling CO₂ into useful products like green hydrocarbons or plastics, cheaper water desalination to solve water scarcity and even turn deserts into oasis
- Far more efficient solar cells (including cheaper processes for silicon-perovskite tandem cells, hybrid tandem cells, and III-V cells)
- Breakthrough battery chemistries like lithium-air batteries or sodium-air fuel cells scaled up to beyond the size of a dime. These have a theoretical density 3x that of any other known chemistry and approach the energy and power density of gasoline.
- Materials for new computing paradigms harnessing alternative physics as I wrote about here, including edge ASICs to power extremely high latency fully on-device robotic VLAs
- Metamaterials for invisibility cloaks, manipulating light for all-optical integrated AI ASICs, next-gen telecommunications like 6G technologies
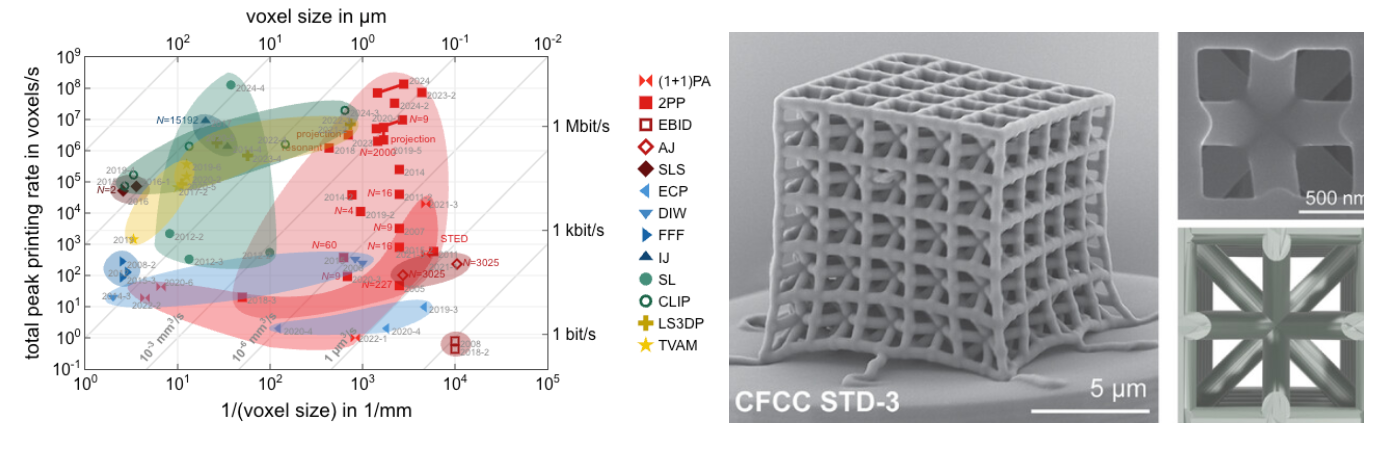
- Nanomaterials that are structured like the Eiffel Tower at the nanometer scale such that it’s as strong as steel despite being 99% air. Imagine airplanes whose frame weighs 1,000lbs… needing almost no fuel, the marginal cost of flying would fall close to zero. This tech is expected to be commercialized relatively soon assuming 3D printing’s speed at these tiny scales continues to rise even close to 1,000x per decade.
- Higher power/efficiency magnets for electric engines, MRI machines (maybe that’s the unlock for a successful, cheap preventative concierge doctor service), fusion, etc.
- Room temperature superconductors, with strange metals appearing the most promising
- Other quantum materials like graphene, 2D transistors or magnonics
- Mass manufactured, cheap diamonds for consumers and for next-gen semiconductors
- Ultra-high performance materials for aerospace including carbon-carbon composites for hypersonics, high temperature ceramics/metal alloys for re-entry, radar-absorbing coatings, novel propulsion chemistries for rockets, micro-asteroid satellite protective shields, etc. Also interesting are novel simulation methods to substitute for expensive physical tests.
- Higher strength metals for building materials, jets, etc.
- Chip- to datacenter-level coolants
- Passive building materials to keep buildings the proper temperature without any energy expenditure or step-function more efficient HVAC / AC coolants
- Cheaper buildings materials for housing
- Coatings resistant to hydrogen induced brittleness to convert natural gas pipelines into trans-continental hydrogen transport
- Metallic glass for high-precision gears
Realizing these materials innovations as well as others we haven’t even dared to imagine yet would help usher in an era of radical abundance.
But to do so, we must shrink the timelines for both the basic research that leads discoveries and the time from discovery to commercialization from 10-20 for each to a few years.
At Compound, we’ve been studying and investing in this space for years, from Orbital Materials pioneering the computational side to Magrathea doing mining-free magnesium extraction.
The field is at a unique junction in time with money starting to gush into materials discovery but with technical solutions only just starting to show commercial prospects. Several humongous seed rounds are in the works while three-year-old companies like Orbital are starting to scale PFM. Moreover, frontier LLM giants may continue to bleed into the category.
Despite this gold rush, no one in the industry can agree on what the hardest part currently is nor the most valuable positioning for a company to own. While disagreement over specific technical implementations or strategies is natural, we have rarely ever seen such disagreement in an industry over what the hard part is.
Computational researchers like those pioneering NNPs tell us the core bottleneck is testing their generated hypotheses at scale
… while those developing the transformative synthesis techniques to do so tell us it’s already largely a solved problem
… while those that work on the translation between the computer and the kiln tell us the integration and retrosynthesis is where the technical whitespace lies.
Will having the absolute best computational talent to devise algorithmic breakthroughs and orchestrate robotic labs scale indefinitely? Or will the synthesis tech to train and test those models be an unavoidable gatekeeper? Will earlier companies’ years of relationship building with the major corporations to whom all startups must sell their materials be a vital sales wedge for the incremental next deal? Or can newer startups king-make themselves by raising ludicrous sums from venture philanthropy?
These questions are currently unknowable but I suspect that the narrative will shift rapidly, dramatically, and repeatedly over the next several years as the field emerges from its currently somewhat niche shadows into one of the hottest areas of tech. How the narrative shapes out in the long-run could be a function of where the money goes in the short-run as much as the stochasticity of technical breakthroughs.
Computationally Predicting Materials Properties
Computational approaches in material science have lagged decades behind those of biology because the field has far more parameters with no evolutionary pressure to reduce the dimensionality. It has more complex chemistries, uses more of the periodic table, and depends upon composition, size, shape, phase structure, the structuring within the particles, etc. There are 1014 seven-component nanoparticles. And, that’s just nanoparticles. Scaling up to bulk materials becomes effectively infinite.
This has made the development of force fields untenable. So the SotA until now has been brute forcing estimations with parallel DFT calculations.
The first and obvious low hanging fruit is replacing those with NNPs, which are the same accuracy but 10K-1M times faster. Universal NNPs should start reaching experimental accuracy for some real-world downstream tasks in the next several years. In just the last several months the following datasets have been released:
- QM25 took 6 billion CPU core hours to generate, 10x larger than any other dataset
- ~400K structures carefully sampled from 281M MD snapshots spanning 16B atomic environments (including high fidelity adjusted r2SCAN data)
- First large-scale computation of QMC forces and energies with selected-Configuration Interaction wavefunctions at the complete basis-set limit
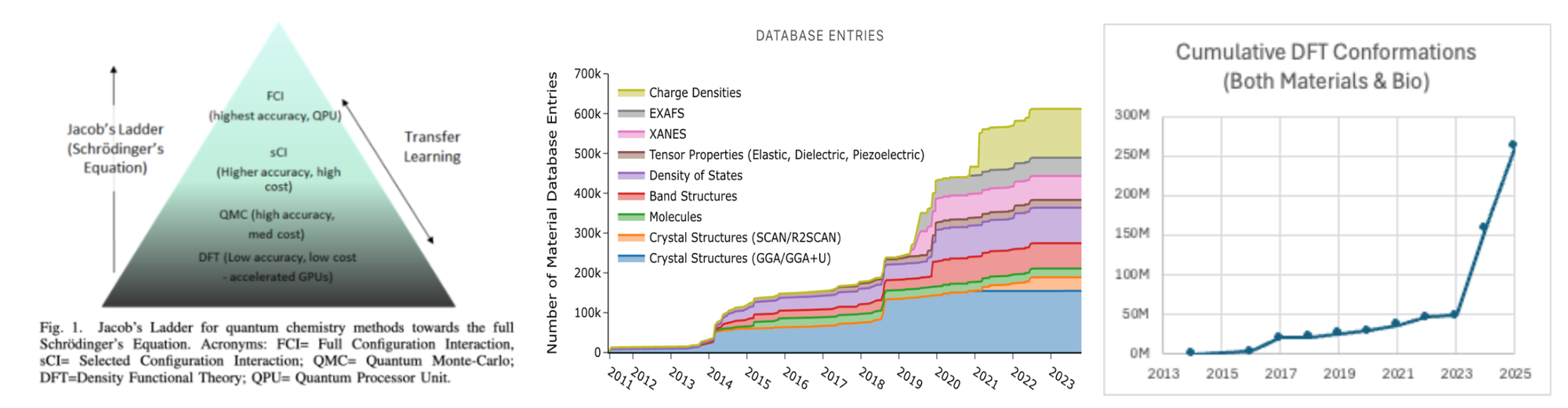
These have helped produce models that are already within ≈1 kcal/mol for large-scale systems at nearly force-field speed.
Excitingly, we’re nowhere near saturation on the algorithm side. While current work has primarily focused on improving base model accuracy with better datasets, architectures, and scaling; the improved model isn’t that useful if it can’t actually be sampled in a feasible amount of time.
We’re still largely running brute-force, unbiased molecular simulations or at best applying traditional enhanced sampling methods on the energy landscapes.
The bleeding edge approaches try to form a hybrid between AlphaFold-like diffusion models and naive simulation. In other words, merging generation and simulation. This could include a loop where a diffusion model proposes configurations, fast ML surrogates of the potential re-weight them, and the discrepancy feeds back in an RL loop to refine both the sampler and force field.
Within just the last two months, the first set of papers have been published hinting at the technical path towards this future. Adjoint Sampling casts sampling as a stochastic-optimal-control task and trains a diffusion process with a “Reciprocal Adjoint Matching” loss, enabling many gradient updates per costly energy call. MDGEN treats an MD trajectory as a “molecular video” and learns a flow-matching generative model over SE(3)-invariant tokenized frames, letting a single network handle forward simulation, transition-path interpolation, frame-rate up-sampling, and molecule-inpainting tasks. A final approach treats the score field of any pre-trained diffusion/flow-matching model as an SDE drift and uses gradient descent on the discretized Onsager–Machlup action to obtain high-likelihood transition paths between fixed endpoints without additional training.
With these processes building upon diffusion research in frontier labs, it’s thrilling that researchers are still finding step function efficiency improvements in diffusion itself.
So where is the research now in terms of practical usefulness? Google’s 2023 GNoME showed that predicting thermodynamically stable structures at zero kelvin was effectively solved. Such generative models can predict candidates at room temperature and NNPs can provide estimations of specific properties that help sort through which candidates to physically synthesize. But directly answering if a material can stably exist and is synthesizable at 300K is still on the immediate horizon.
Ultimately all this work could plausibly yield quantum chemical accuracy with better-than classical force-field speed on real-world tasks within five or so years.
Large-Scale Synthesis Screening or Testing Model Predictions IRL
Materials synthesis has a reproducibility crisis possibly deeper than that of biology. The main material that doesn’t face challenges is semiconductors because the industry has spent trillions of dollars over decades making atomically precise automated equipment.
If synthesizing a single novel material reliably has been hard, doing so for millions of predicted structures simultaneously has historically been effectively impossible. Indeed, computational researchers we spoke with still consider it the hardest part of materials science.
However, a couple pioneering groups have recently developed extremely high-throughput nanoscale printers for various materials classes.
They both believe they’ve effectively solved large scale screening of metal groups and nanoporous materials respectively.
They skip the computational component for now and use their tech to screen massive libraries IRL. Their view is that whereas NNPs and generative models trained on DFT simulation, the way forward is using their incredibly high throughput tools to generate the PDB equivalent of materials science and train models based on these standardized, uniformly generated, high-precision experimental datasets.
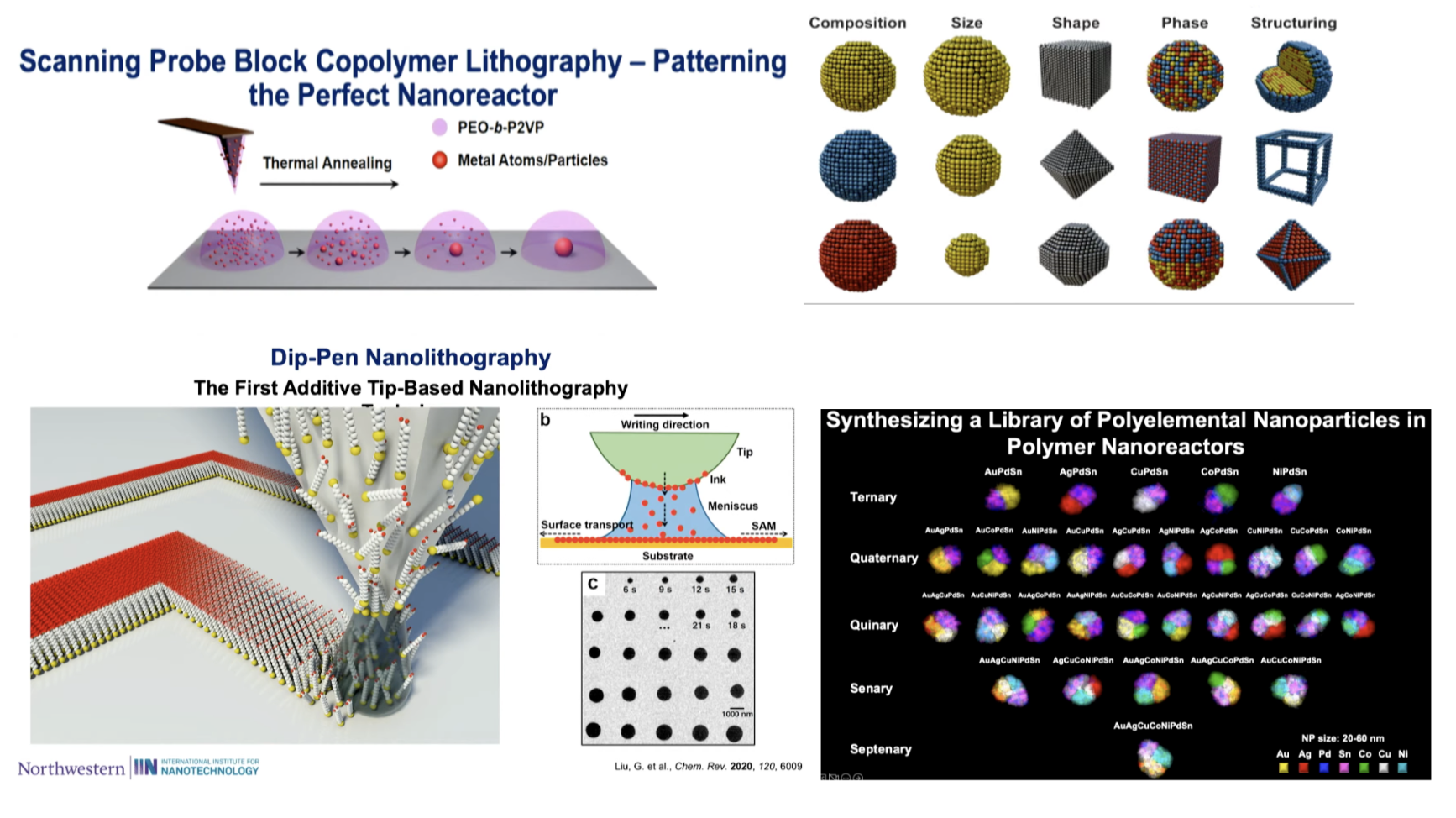
A spinout of Chad Mirkin’s group is utilizing his Dip or Polymer Pen Nanolithography techniques to generate on demand libraries of up to 56M unique nanoparticles with gradients of composition, size, and structure. They can combine up to seven different elements into one phase segregated nanoparticle and can now cover 52+ elements.
With this tech, they’ve printed 5B particles cumulatively when the world has made and characterized less <1M new inorganic materials. In fact, they consider largely solved inorganic mixed metals, metal sulfides, and mixed metal oxides that come in different forms. Also fair game are structures like halide perovskites, quantum dots, carbon-walled nanotubes – most combinations with solvent/reactor and precursor compatibility are feasible.
Meanwhile, a group from the Netherlands that spun out academic work being developed since the 80s were the only ones capable of answering Meta’s call when they wanted to synthesize >500 different nanoporous material compositions across 13 elements in a short timeframe.
VS Particle developed a machine that employs spark ablation to deposit any conductive material onto nanoparticles of arbitrary shape, size, and composition. It allows for combinations of ~70 elements.
Spark ablation uses ∼10 μs electrical discharges to heat an electrode to ≈20,000 K, vaporizing material that expands into a rapidly quenched gas (≈10⁷ K·s⁻¹ cooling). Then that metal vapor cloud is mixed with an aerosol of core particles, resulting in homogeneous nucleation growth of the coating material.
Since launching in 2014, the company developed a 100x higher throughput machine to go from 300 sparks per second to 20,000 and move up from small-scale academic research to R&D JVs with large corporations.
After that machine’s launch this year, it will build a system that seamlessly connects 10 of its next-gen modules to enable the mass manufacturing of nanoporous materials in which they could produce 100nm-thick surfaces 10s of cm in dimension in hours. It’d be the first time in history that one could go from R&D at the nano-scale to mass manufacturing that discovered material in one fell swoop.

Even as these technologies have pushed the bounds on synthesis throughput, one still must characterize each nanoparticle to measure the properties of what was actually created. Common tools for measuring basic properties universally relevant across all materials classes like structure, composition, etc. include SEM, EDX/EDS, XRD, 4D-STEM. These are starting to become automated but industry participants told us this is understood in the lab, but not at industrial reliability where you can fully trust the data and then train algorithms. Additionally, each class of material and each downstream product requires some special characterization (e.g. parallelized electrocatalytic measurement for electrolyzers).
An open question in synthesis is that even if VS Particle and Mattiq have roughly solved nanoporous and certain metals respectively, do we still need such radical inventions developed by the world’s top labs over 3-5 decades for each class of materials? Or can these companies continue to expand materials classes and size scales? Moreover, even a fully generalized synthesis platform would run the problem of also creating highly automated characterization methods for all different materials types from nanoscale to bulk, which is non-trivial.
Predicting Scale Up from Nanoscale and Retrosynthesis
Even if one solves the design and synthesis of nanoscale materials hits, a host of grand challenges remain to a viable industrially scaled material.
Can you predict how nanomaterials will perform at bulk scales, including under industrial conditions and after thousands of cycles?
The scaling properties of generative models and NNPs will likely prohibit them from ever analyzing macroscale or bulk materials. For that, entirely different methods are used as seen below. How do you build models that can connect those wildly disparate scales modeled with disparate physics?
Multiscale modeling broadly is a fascinating frontier that I’ll be writing about soon.
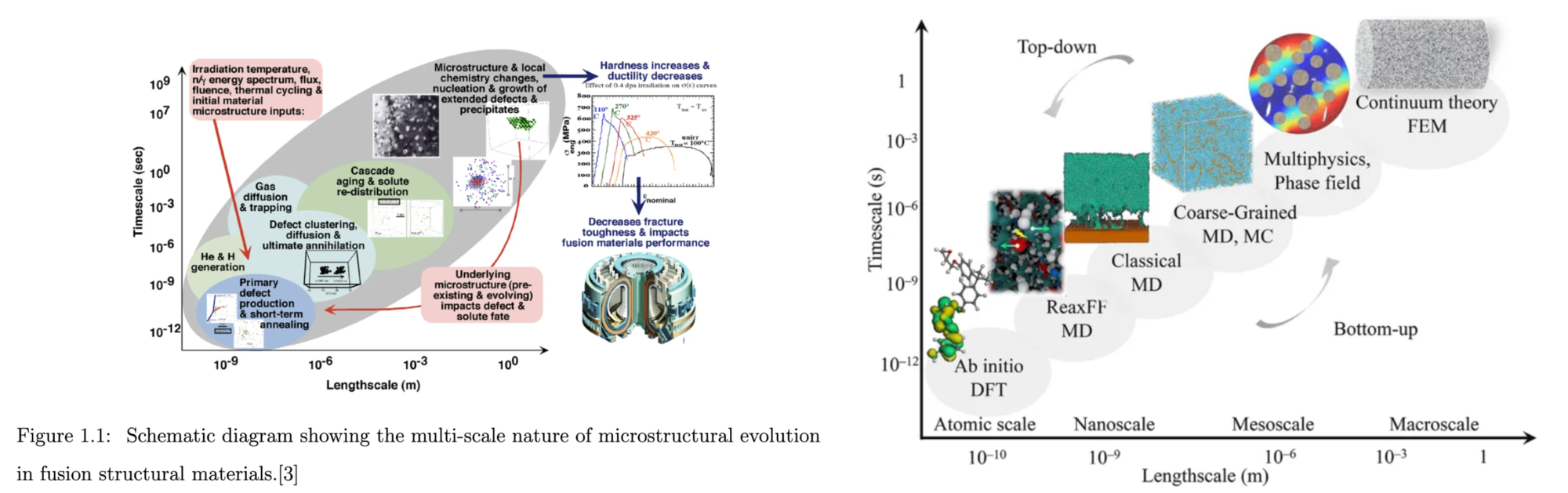
The most general method for relatively simple materials is doing the grunt work over time of scaling up ones’ nanomaterials, testing their bulk and industrially degraded properties, and then finding patterns in the resulting dataset.
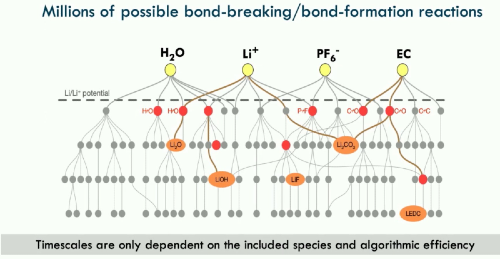
More complex material processes may require correspondingly complex modeling. For instance, easily the strongest such demonstration I’ve seen is from the great Kristin Persson in which works on computing from first principles the solid-electrolyte interface of Li-ion batteries.
The problem includes computing thermodynamics, transition states, and kinetic barriers over a mess of hundreds of millions of possible bond-breaking reactions that are all thermodynamically downhill and cannot be coarse grained. Worst of all, it happens over hours or days, not nanoseconds.
Her method abstracts out time by treating each bond-breaking/forming event as a modular “LEGO” piece. The system starts computing individual LEGO pieces, then uses AI to predict which piece to do next, and finally uses kinetic Monte Carlo and path finding algos to try to traverse the possible configurational pathways to figure out what forms and benchmark against known experimental results, pathways.
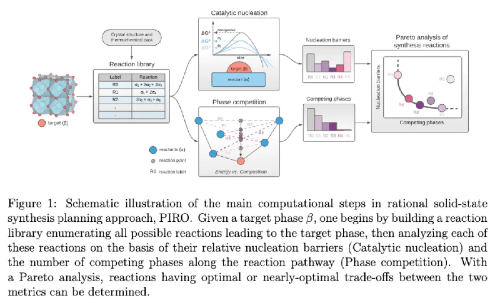
Can you predict the step-by-step procedure to manufacture the material provided an inputted structure and vice versa?
Inorganic materials can’t be synthesized through a sequence of elementary reactions like organic compounds because their formation involves collective nucleation and growth processes governed by complex thermodynamics and transport phenomena, rather than discrete bond‐forming steps. As a result, there’s no general retrosynthetic framework for solids, and their preparation still relies on one‐shot precursor reactions and extensive trial‐and‐error.
In addition to academic groups making headway, a new FRO is seeking to strictly focus on solving this problem, using a self-driving lab to generate a dataset with over 100k manufacturing recipes and then build the capability to do that repeatedly thereafter in under six months and $1M each vs the $20M and 50 years it takes today even after their group’s pioneering work.
Closing the Loop Entirely
Training atomistic NNPs/GenAI models’ structures directly on experimentally synthesized structures is effectively impossible given no method can reliably print at the resolution of atoms. Even using the downstream properties characterized with for example XRD can be used as a reward signal but even getting that loop working is highly non-trivial.
What if you wanted to remove human intervention entirely? Autonomous, self-driving labs (SDL) is now the hot thing with many startups now launching on the premise. The most impressive such demonstrations in materials science have probably been A-Lab and AC / Meta’s work.
For more information on these topics, we at Compound have written extensively on autonomous science from the technical perspective to the commercial side, including even hosting a mini conference.
SDL may prove to be a tool not only to increase the scale of science while decreasing costs, but also to learn the meta of doing science itself to achieve ASI. That’s the bull case for the mega seed rounds. However, at that point, you’re competing head-to-head with OpenAI, Anthropic, Google, Isomorphic, etc. who have infinitely more reasoning data across many domains and whose base models are already showing hints of one-shotting chemistry & biology problems. Maybe building proprietary scientific experimental trajectories on top of a DeepSeek base model is good enough, but maybe not. Thank god for venture philanthropy.
Business Model
All told, materials science is a remarkably hard technical challenge. The business side may be even harder.
Materials in and of themselves aren’t very valuable. It’s the downstream products and societal solutions they enable. The raw materials of an iPhone only cost ~$40. More valuable are materials processes (e.g. mass manufacturing diamonds), end products with large materials science components (e.g. iPhone) and the tools that use materials science to make those things happen (e.g. ASML’s EUV machines).

So, a startup focusing on expediting materials discovery must begin by supplying innovation to major incumbent materials science-related companies.
Similar to platform biotechs being judged entirely by their first target, picking the right first product and industry is existentially important. Unfortunately, there’s no obvious choice. Even sectors like datacenters with the most urgent, deepest pocketed customers have slow, relationship-based sales/pilot cycles. Aerospace is another intuitive starting point but carbon fiber’s diffusion is illustrative: despite its revolutionarily light weight and stiffness being perfectly suited, it took 20 years from its discovery to be used in aerostructures and more than 30 years before it became the primary materials for Boeing 787’s.
The ideal customer is highly innovative in that they understand the need for change but not necessarily sophisticated.
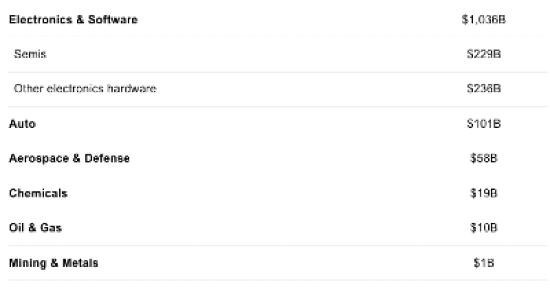
US-Only Industrial R&D Spend in Inorganic Materials by Sector
The contract terms aren’t exactly easy either. The incumbent may be concerned about even defining the problem to solve, as that’s viewed as IP. Then, there’s debates about who owns the data. Most important of all is payment structure. In the pursuit of climbing up the value chain as high as possible, the best case is generally an 8-figure JV with phased payments ultimately resulting in a PoC that the incumbent then scales with their manufacturing / distribution base and ideally pays some ongoing royalty for.
For more historical color on the commercial path to bringing a novel material to market, see these three resources. They broadly stress the importance of thinking harder than materials scientists are used to very early on about the minute details of its commercial integration, minimizing the complexity of value chain integration (drop in, modular, etc.), and leaning into smaller, fast growing markets uniquely enabled by the new technology as opposed to first starting with the largest, homogeneous ones.
All together, to become a truly massive business you either need to:
- Fully achieve the mission of shrinking time to market from 15 to 1.5 years and consistently spin off 8+ figure JVs or play in a market so large it generates $100M+/yr
- Become the operating system for the materials science ecosystem: a largely software platform embedded across industries and geographies, empowering the materials scientists at the many $10B+ materials-focused companies. By building an engine for end-to-end development from problem to materials discovery to end product, you may have a tool strong enough to finally start building and owning end products yourself.
- Make a killer end product yourself, but that’s a 10-20+ year company in itself
A Post-AGI Materials Discovery Company
The world is about to get really weird. AGI may be achieved within 5 years with fairly high likelihood. And, it’s unlikely that we’ll simply stop development at GPT6.
Coding appears to be a couple years away from being effectively solved. Maybe robotics advances will even make physical manipulation arbitrarily easy within 10 years.
For a truly outstanding perspective on how this future might unfold, read this series called A History of the Future.
The most interesting question of this whole piece to me occurs in 8-10 years at the intersection of a post-AGI world and when the materials discovery problems detailed above have largely been solved by the ever rising wave of world class startups.
In ten years, we might also have useful quantum computers that make materials discovery that much more trivial.
In such a world where:
- Materials discovery has truly been compressed from decades to months
- You can spin up as many elite digital and even physical agents on demand
Then can the currently somewhat slow and painful business model of generalized materials discovery startups be reinvented?
Could you build the Genentech of materials: the first-ever company whose core competency is building a materials discovery engine that doesn’t stop at handing off initial PoC hits to incumbents but instead owns entire value chains by spinning up AGI workers to orchestrate product and business development?
Owning full value chains while simultaneously keeping the core competency of building the materials discovery engine is of course currently impossible because managing a single business as broad as “commercialize this new solar cell material” is a 10-20 year mission requiring huge teams and resources in themselves.
But we at Compound feel that AGI is possibly impending and it feels increasingly plausible that such an audaciously ambitious company could be feasible in that future.
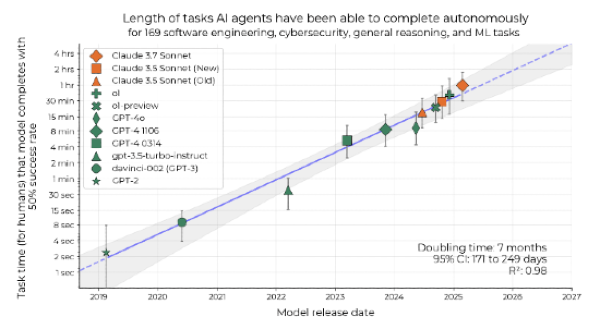
For what it’s worth, if current trends of agent task length doubling every six months is naively extrapolated, then that implies AI agents capable of working autonomously for 6 months straight in six years in 2031. Then 2 years straight in 2032. Then 8 years of autonomy in 2033.
Perhaps you could set up a swarm of ASI scientists and AGI agents to:
- Run millions of simulations daily
- Orchestrate a network of 50 autonomous labs worldwide, each running different synthesis and characterization techniques
- Design custom production equipment
- Simulate supply chains, optimizing for local regulations, costs, and resource availability
- Identify unmet market needs by analyzing exabytes of human behavior data
- Create and manage brands
- Handle customer relationships at scale
If you allow the possibility of such a future, some other interesting questions emerge.
With semiconductors being the only truly thriving ecosystem in materials science, how would the structure of the industry have looked if it had gotten started a few years before AGI/ASI?
What products should you seek to own the entire value chain for vs the capital light path of doing JVs for manufacturing? Maybe the intuition should be to do JVs for materials where the material itself accounts for a large portion of the item’s downstream value, the production complexity is low, and it serves no strategic purpose to the company. GORE-TEX should be licensed out to Arc'teryx as the material represents much of the value of a textile that’s low value to begin with. And while maybe an AI ASIC would be feasible, the developer ecosystem necessary to build an iPhone competitor would be impossible.
Similar to how it’s hard to predict past the event horizon of AGI, it’s both hard and wondrously exciting to imagine a world in which we can design materials de novo to solve arbitrary problems.
Towards Abundance
Regardless of whether that particular future plays out, we at Compound are excited about companies pushing forward high-value parts of the materials science stack. As discussed throughout this post, that includes novel synthesis technologies, manufacturing processes, experimentally accurate computational methods, and product-focused startups that only press on a single technology vector or on integrating a few technologies.